TL;DR: faf-rust-sdk v2.0.0 ships the FAFb binary format — built for enterprise scale, future-proofed for any repo size, complexity, or organization. Every YAML key becomes a named binary section. No hardcoded limits. No artificial ceiling. Free upgrade, MIT license, IANA-registered open standard.
Why This Exists
In the early 90s, I was working with computer graphics engines and apps on the Amiga. The file format underneath everything was IFF — the Interchange File Format that Commodore created. Chunked binary. Named sections. Extensible without breaking readers. It was elegant. It worked.
That architecture influenced everything that came after. Microsoft literally riffed on it with RIFF. ELF uses the same pattern for executables. Decades later, these formats still work because the core idea was right: named chunks, a table of contents, and the freedom to add new chunk types without breaking old readers.
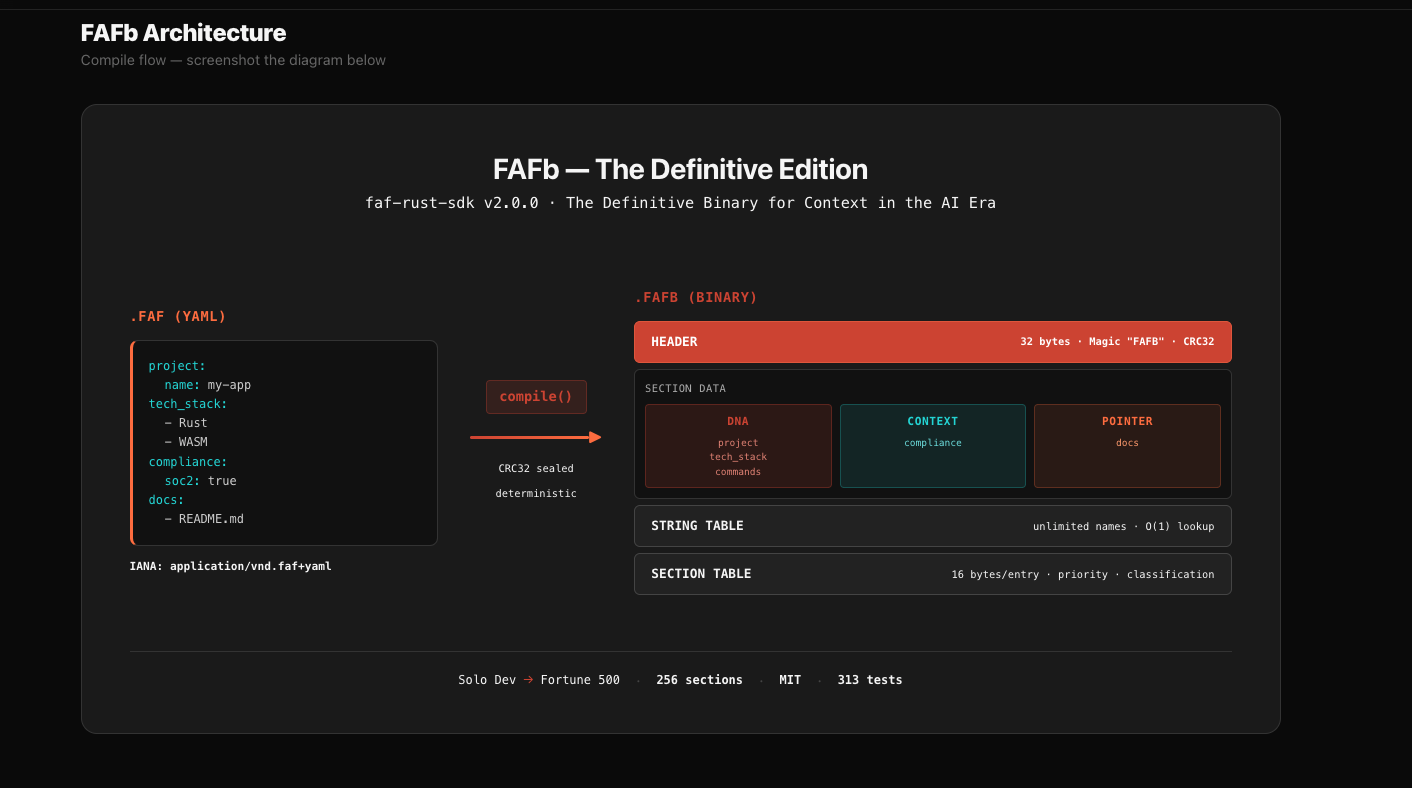
When FAF needed a binary format, that knowledge was already there. The insight was simple: every YAML key in a .faf file can just become a named section in the binary. No hardcoded enum with 11 types. No "Unknown" fallback. A string table — the same pattern IFF and ELF have used for decades — indexing unlimited section names.
v1 was the proof of concept. It worked, but it had a ceiling. v2 removes the ceiling. A solo developer's .faf file compiles to the exact same binary format as a Fortune 500's. Same header. Same sections. Same classification. The format doesn't care about your org chart — it scales from a side project all the way to xAI or SpaceX, and all the way back to earth. This is the format we always wanted to ship.
What's New
String Table
Every YAML key becomes a named binary section via a string table — up to 256 sections per file. No hardcoded types. Custom fields like compliance, security, or agents serialize just as cleanly as project or tech_stack.
Chunk Classification
Every section is automatically classified:
- DNA — core project identity (
project,tech_stack,commands,faf_version) - Context — supplementary chunks (
compliance,security,agents, custom fields) - Pointer — documentation references (
docs)
Classification is baked into the binary at compile time. AI readers can prioritize DNA sections first, load context on demand, and follow pointers when needed.
Enterprise Scale
Tested against Titan fixtures — 680 engineers, 62 teams, 240 repos. The format handles it. Priority truncation means an AI with a 4K context window gets the DNA sections first. An AI with 200K gets everything.
Deterministic Output
Same YAML in, same binary out. Every time. CRC32 of the source YAML is sealed into the header. No timestamps unless you ask for them.
The Binary Layout
HEADER (32 bytes)
Magic: "FAFB"
Version, flags, section count, CRC32 checksum
SECTION DATA (variable)
Each YAML key → one section, priority-ordered
STRING TABLE (appended)
Section name index — unlimited names, O(1) lookup
SECTION TABLE (at end)
16 bytes per entry: name, priority, offset,
length, token count, classificationUse It
Rust
cargo add faf-rust-sdk use faf_rust_sdk::binary::{compile, decompile, CompileOptions};
let yaml = "faf_version: 2.5.0\nproject:\n name: my-project\n";
let opts = CompileOptions { use_timestamp: false };
let bytes = compile(yaml, &opts).unwrap();
let result = decompile(&bytes).unwrap();
let dna = result.dna_sections();
let ctx = result.context_sections();WASM (Browser / Edge)
npm install @faf/wasm-sdk import init, { compile_fafb, decompile_fafb } from '@faf/wasm-sdk';
await init();
const bytes = compile_fafb(yamlContent);
const json = decompile_fafb(bytes);The Numbers
- v2.0.0 — Released March 19, 2026
- 175/175 — faf-rust-sdk tests passing
- 138/138 — faf-wasm-sdk tests passing
- 313 total — across both SDKs
- MIT — free, open, forever